An Uniform Resource Locator or URL is the unique address of a file on the Internet.
An URL is composed by the protocol, the host name (that corresponds to the host’s Document Root on the host filesystem), and the relative path of the file to be loaded (with respect to the Document Root). This was the short version.
We will now discuss in detail the various parts of an URL not before having explored a few connected concepts, namely:
– Hosts
– Host Names (see also here)
– Virtual Hosts
– Domains
– Document Roots (already discussed here)
If you think I am tricking you into accessing a chapter with an easy title (URL? Yeah, I know what it is), to then deviate toward complicated and unexpected arguments, you are right. There is a complains box at the bottom of this page called “comment”, feel free to use it 🙂
Actually there is a reason for discussing hosts, domains, Document Roots together with URLs: there is an (apparently) intricate relationship between those objects that you, as a Bioinformatician who wish to contribute to the growth of the Internet and the progress of Science by designing your own original web applications, are expected to fully master. Carry on!
Hosts
Each file on the internet is located on a certain “host”, a computer connected to the internet.
In current language, host is also a synonym of “host name”: depending on the context, host could indicate the physical machine connected to the internet, or an host name “hosted” on this machine.
The host name will be associated to an host IP address by the DNS system.
So we say that an host (machine) can host an host (host name). Looks like a linguistic joke, but this is how things really stand in human language sometimes. This kind of ambiguities may explain in part why it is so difficult to convince computers to understand human speech, but this is another story.
Examples of host names on the internet could be:
– www.cnn.com
– news.cnn.com
– nih.gov
– www.ncbi.nlm.nih.gov
These are different 4 hosts, related to two different domains (cnn.com and nih.gov), that could be, in theory, managed by four different computers, or by a unique physical machine, depending on how the DNS for these host names is set.
Indeed a single machine/host/IP address can manage various host names at the same time. In Apache this is done by configuring VirtualHosts.
Apache Virtual Hosts
Apache allows to set up a number of Virtual Hosts, one for each host name we wish to serve from our machine. Then we can point the DNS records for all these host names to the IP of our machine, so that visitors to the hosts will be directed to our machine and served the correct files and services.
Example 3-1-1: An Apache configuration file that defines two VirtualHosts
By using Apache Virtual Hosts, it is extremely easy to assign a dedicated Document Root to each of the hosts managed by a machine. This is the secret for hosting several, even hundreds of different websites on a single computer with a single IP address.
In the following example, you see an Apache configuration file, normally located at:
/etc/apache2/sites-enabled/000-default
that defines 3 hosts for the cellbiol.com domain and their respective Document Roots, by using 2 VirtualHosts directives.
Mind that this is an hypothetical Apache file, our web setup is entirely different from this. However the indicated document roots are consistent with what you can check on the web cellbiol.com website at the url level.
The first VirtualHost defines the web root for the www.cellbiol.com host, that is /var/www. The server has a server alias, cellbiol.com. The alias will share the same DocumentRoot as the server it is associated with:
www.cellbiol.com and cellbiol.com (2 host names)
DocumentRoot: /var/www (1 Document Root)
The second host name is defined as an alias of the first with the
ServerAlias directive, see the file below.
You can check that visiting http://cellbiol.com or http://www.cellbiol.com will give the same results (at the time of this writing!).
The second VirtualHost defines the web root for the games.cellbiol.com host. This is /var/www/games. So the “games” directory, Document Root of games.cellbiol.com is a child of the www.cellbiol.com Document Root. /var/www/games is a child directory of /var/www.
If this was true, you would expect to be able to reach:
http://games.cellbiol.com at http://www.cellbiol.com/games. Check it out (don’t have too much fun with the games though, back to work immediately!).
Below, find the contents of the hypothetical /etc/apache2/sites-enabled/000-default file described above.
<VirtualHost *:80>
DocumentRoot /var/www
ServerName www.cellbiol.com
ServerAlias cellbiol.com
</VirtualHost>
<VirtualHost *:80>
DocumentRoot /var/www/games
ServerName games.cellbiol.com
</VirtualHost>
Domains
A minimal host name can be composed by just the “domain”. The “domain”, as the term is used in current language, is composed by a first or top level domain (.com, .org, .net, .gov etc..), that identifies broadly the kind of domain, and a second level domain (cnn, nih, cellbiol in the examples above), whose name was chosen at the time of registration by the registrant.
A domain (first level + second level) identifies a defined “entity” (organization, business, online shop, university, newspaper, travel agency, blog etc..).
Some entities are relatively small and will typically accessible at 2 different host addresses: the basic domain address, and the corresponding third level address “www”.
– organization.org
– www.organization.org
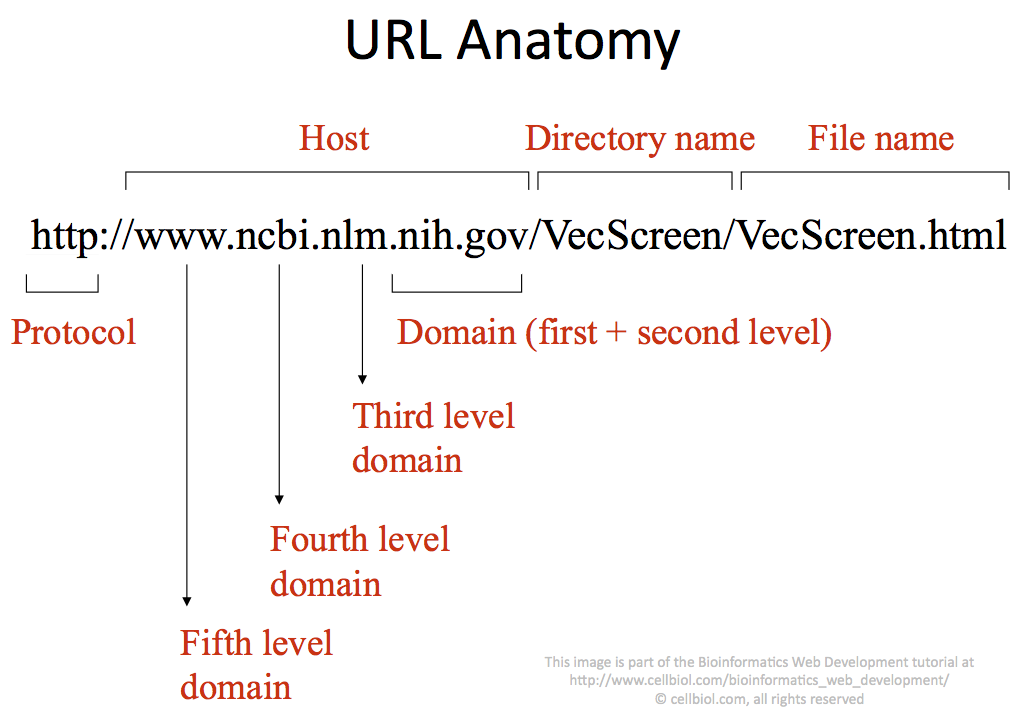
In the latter address, “org” is the first or “top” level domain, “organization” the second level domain and “www” the third level domain (see also figure 3-1-1).
The DNS for these two addresses might be set to point them to the same IP, and the Apache on the host computer may be configured to assign the same Document Root to both host names, as done in the first VirtualHost in cellbiol.com example above.
On the other hand, in the case of a bigger organization such as a University, a Campus, a big company, it is possible that several third level domain names exist in addition to the classical “www”, corresponding to entirely different websites, maybe (but not necessarily) hosted by different computers. For instance each department or faculty could have it’s own third level domain, maybe hosted by a Faculty/Department server:
– www.organization.org (organization home page)
– biology.organization.org
– neuroscience.organization.org
– bioinformatics.organization.org
– molecular_medicine.organization.org
– ……
A particular third level domain could then father several fourth, fifth, or higher level domains. In the example in figure 3-1-1, which corresponds to a real web page on the NCBI website, the host name comprises 5 domain levels.
URLs
With this background information, we can understand the anatomy of an URL (figure 3-1-1).
– The very first part is the TCP/IP application protocol. For web pages this will be http or https (Hyper Text Transfer Protocol or it’s secure version).
– Then follows the host name. You see how this is essential, this is the information about the computer connected to the Internet that actually hosts the requested file on it’s filesystem. An URL with the host name alone (this would be http://www.ncbi.nlm.nih.gov/) serves the files contained in the host’s Document Root (by definition of DocumentRoot). So visiting http://www.ncbi.nlm.nih.gov/ is equivalent to visiting the Document Root of the www.ncbi.nlm.nih.gov host, as set in the host’s Apache configuration files.
– The last component of the URL is the path of the actual file to be served, “VecScreen/VecScreen.html” in the example below, with respect to the DocumentRoot directory.
The relationship between a web file URL and path on the host’s filesystem is further clarified by figure 3-1-2.
The URL request, from a browser on a client computer, to an internet server reachable at a particular host name, can be better read from right to left.
A request for:
http://www.ncbi.nlm.nih.gov/VecScreen/VecScreen.html
Means: “send me the VecScreen.html text file which is located in the VecScreen directory of host www.ncbi.nlm.nih.gov. Use the http protocol.”
Host name:
www.ncbi.nlm.nih.gov
Host’s Document Root:
/var/www (purely hypothetical, we don’t know the actual web root of this host!)
Host’s URL:
http://www.ncbi.nlm.nih.gov/ (the final slash is usually optional.
By definition, the “base URL” of an host, the URL that contains just the host name, corresponds to the Apache’s DocumentRoot on the host)
________________________
VecScren directory URL:
http://www.ncbi.nlm.nih.gov/VecScreen/
VecScreen directory path on the www.ncbi.nlm.nih.gov host:
/var/www/VecScreen
________________________
VecScren.html file URL:
http://www.ncbi.nlm.nih.gov/VecScreen/VecScreen.html
VecScreen file path on the www.ncbi.nlm.nih.gov host:
/var/www/VecScreen/VecScreen.html
URLs could include a complex subdirectories hierarchy such as
http://hostname/dir1/subdir1/subsubdir1/file.html
which could correspond to a path like this on the host’s filesystem:
/var/www/dir1/subdir1/subsubdir1/file.html
The relationship between a web file URL and it’s path on the host computer filesystem is illustrated in figure 3-1-2.

Course setup
A common setup that we encounter during this course is based on a computer connected to the internet with a public IP address, and no host name associated with it. URLs in this case will have an IP in place of an host name. The document root of your files could be /var/www/html (current Apache’s default), if you are the administrator of your own machine, for example your laptop.
In this case, your base URL will be just your IP, for example:
http://122.13.22.34/
The Document Root of your files could instead be /home/username/public_html if you have an account on a machine shared by several users/students. In this case, if the server was setup as described here, your base URL will be something like:
http://122.13.22.34/~username/
You now know where to put one of your web files in your filesystem to make them accessible at a particular URL for the world. This is a good starting point. Let’s add a little important piece of information.
The special index.html or index.php files
If a directory within the Document Root, including the Document Root itself, contains a file called “index.html” or “index.php”, this file will be shown by default on visiting the URL of the directory. You can easily check, for example, that when you visit:
http://www.cellbiol.com
you are actually viewing the file:
http://www.cellbiol.com/index.php
This allows to have shorter and somewhat cleaner URLs.
Directory listing
By default, in most cases, Apache is configured to show the contents of a directory to visitors unless an index.html or index.php file is present (in this case the index file is shown instead). Therefore, creating an index.html file in a directory, even an empty index file, is a quick and easy way to conceal the directory contents to visitors.
A cleaner way to conceal directory contents even if an index file is not present is to configure Apache so that it does not show the directory contents by default, and for example, issues a “Virtual Directory Listing Denied” error if the index file is not present. This is achieved by including the appropriate directives in the Apache configuration file, see here for more details.
Chapter Sections
[pagelist include=”135″]
[siblings]